字典
Redis数据库的底层实现使用的是字典数据结构,对数据库的增、删、查、改都是在对字典进行操作。
其底层实现是哈希表,每个哈希槽存放键和值两个数据,使用链表来处理哈希冲突。哈希算法使用的是MurmurHash2算法。如下图:
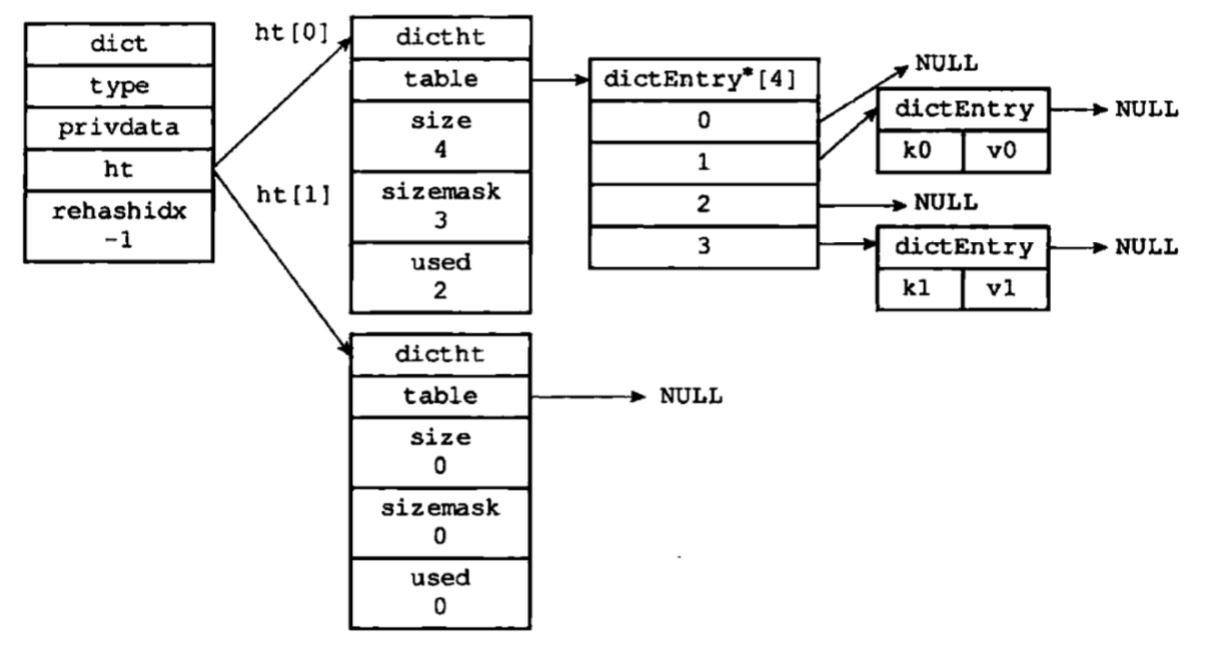
图中有两个哈希表,ht[1]主要是在rehash的时候当作过渡用,Redis的rehash是渐进式进行的,不是一次性完成rehash,这样做是为了避免当哈希值比较多时一次性rehash会导致服务器在一段时间内停止服务。渐进式rehash的详细过程:
- 为
ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表。 - 在字典中维持一个索引计数器变量
rehashidx,并将他的值设置为0,表示rehash工作正式开始。 - 在rehash进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当rehash工作完成之后,程序将rehashidx属性的值增一。 - 随着字典操作的不断执行,最终在某个时间点上,
ht[0]的所有键值对都会被rehash到ht[1],这时程序将rehashidx属性值设为-1,表示rehash操作已完成。
渐进式rehash的好处在于它采取分而治之的方式,将rehash键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,因为rehash的过程中同时有两个哈希表存在,所以在此期间字典的删除、查找、更新操作都会在两个哈希表上进行,例如在字典中查找一个键,程序会先在ht[0]里面查找,如果没有找到则继续在ht[1]中查找。但是在添加键值对操作时新的键值对会一律保存到ht[1]里面,不会对ht[0]做任何添加操作,这是为了保证ht[0]键值对的数量只能减少不能增加。
跳跃表
跳跃表是一种有序数据结构,他通过在每个节点中维护多个指向其他节点的指针,从而达到快速访问节点的目的。 跳跃表支持平均O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。在大部分情况下, 跳跃表的效率可以和平衡树相媲美,并且因为跳跃表的实现比平衡树更为简单,所以可以使用跳跃表来代替平衡树。 Redis使用跳跃表作为有序集合键的底层实现之一。
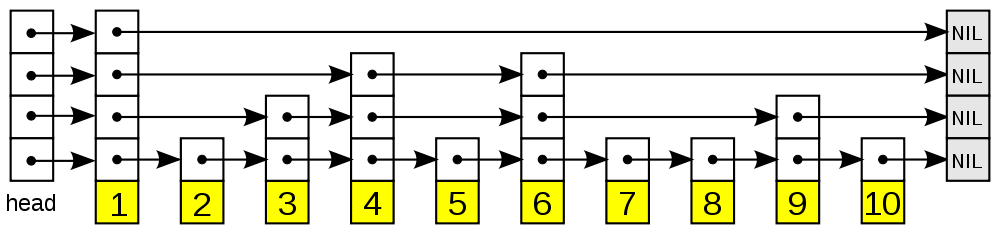
跳跃表主要由以下部分构成:
表头(head):负责维护跳跃表的节点指针。
跳跃表节点:保存着元素值,以及多个层。
层:保存着指向其他元素的指针。高层的指针越过的元素数量大于等于低层的指针,为了提高查找的效率, 程序总是从高层先开始访问,然后随着元素值范围的缩小,慢慢降低层次。(层的高度是随机生成的)
表尾:全部由 NULL 组成,表示跳跃表的末尾。
具体查找、插入、删除过程参考浅析SkipList跳跃表原理及代码实现
过期键删除策略
Redis允许使用EXPIREAT命令或PEXPIREAT命令,以秒或者毫秒精度给数据库中的某个键设置过期时间。 expires字典保存了数据库中所有键的过期时间,我们称这个字典为过期字典:
- 过期字典的键是一个指针,这个指针指向键空间中的某个键对象。
- 过期字典的值是一个long long类型的整数,这个整数保存了键所指向的数据库键的过期时间,一个毫秒精度的UNIX时间戳。
Redis有两种删除策略:
-
惰性删除策略
惰性删除策略是在所有读写数据库的Redis命令执行之前都会调用
expireIfNeeded函数对输入键进行检查:- 如果输入键已经过期,那么
expireIfNeeded函数将输入键从数据库中删除。 - 如果输入键未过期,那么
expireIfNeeded函数不做动作。
expireIfNeeded函数就像一个过滤器,它可以在命令真正执行之前,过滤掉过期的输入键,从而避免命令接触到过期键。 - 如果输入键已经过期,那么
-
定期删除策略
定期删除策略就是定期遍历数据库,判断是否过期,如果过期就删除对应的键值对。Redis中不是一次性遍历整个数据库, 而是在规定的时间内分多次遍历服务器中的各个数据库,每次遍历检查一部分键的过期时间。
Redis键的过期时间都保存在expires字典中,过期字典的键是一个指针,这个指针执行键空间中的某个键对象(也就是某个数据库的键),
过期字典的值是一个long long类型的整数,这个整数保存了键所指向的数据库键的过期时间–一个毫秒精度的UNIX时间戳。
RDB与AOF持久化
RDB
RDB持久化的意思是遍历Redis内存中的所有数据,将数据挨个存储到磁盘。
有两个Redis命令可以用于生成RDB文件,一个是SAVE,另一个是BGSAVE。SAVE命令会阻塞Redis服务器进程,直到RDB文件创建完成,在此期间不处理任何命令请求。
而BGSAVE命令会派生出一个子进程,然后由子进程负责创建RDB文件,父进程继续处理命令请求。可以设置定时或者达到设置的条件之后进行持久化。
RDB持久化的缺点:因为每次持久化都需要遍历所有数据并将数据写入磁盘,此时会产生大量磁盘IO,影响服务器性能,并且不能实时保存数据(每间隔一段时间持久化一次),所以还是有部分数据丢失的风险。
AOF
AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库的状态。用户每次执行的写数据命令完成之后,都会将命令完整保存到文件中, 当需要恢复数据时Redis会读取文件中的所有命令记录并执行。
因为AOF是保存命令执行记录来进行持久化的,所以AOF文件会越来越大,文件过大可能会对服务器造成影响,使用AOF文件进行数据还原的时间也会越来越长,并且其中的很多命令对于最终的结果来说可能都是无效的。
所以Redis提供了AOF重写的功能,AOF重写是通过遍历当前数据库中的所有数据,然后将每条数据组合为一个写命令来实现的。也就相当于每条数据只需要一条命令来恢复。
主从同步
从服务器首先会同步主服务器上的所有数据,主服务器收到同步命令之后,会创建一个RDB文件,然后将RDB文件发送给从服务器(在RDB文件同步期间,主服务器会缓存这期间的写命令,RDB同步完成之后将缓存的命令也同步到从服务器), 从服务器利用RDB文件恢复到当前状态之后,接下来主服务器上执行的写命令都会同步到从服务器,从服务器也会执行这些写命令保持与主服务器的数据一致。
主服务器也会给写命令维护一个复制积压缓冲区(一个固定长度的先进先出队列),用于解决主从断开连接,又重连之后同步断开期间的写命令。
Redis集群
Redis集群无中心结构,每个节点都和其它节点通过互ping保持连接,每个节点保存整个集群的状态信息,可以通过连接任意节点读取或者写入数据。
redis集群分为16384个槽,某个key落到哪个槽的算法:CRC16(key)%16384的值;
需要预先配置每个节点负责的槽,只有当所有槽都分配到节点上之后Redis集群才进入上线状态提供服务。
集群中每个节点都分成一主多从,避免单点故障;
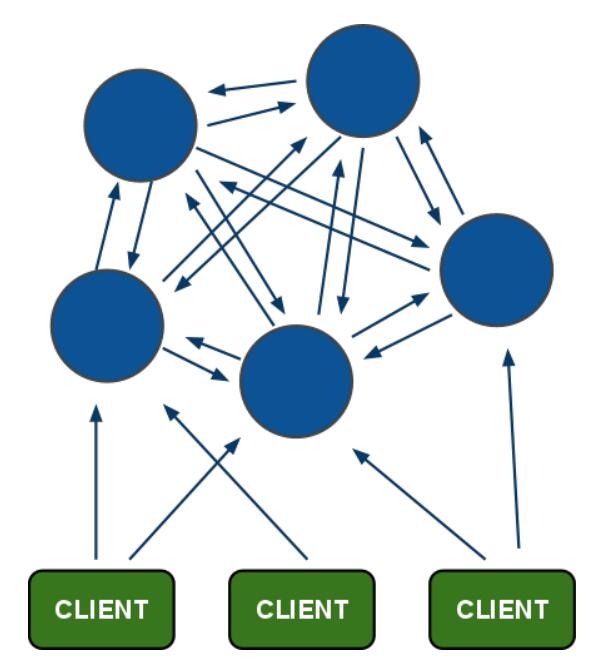
当客户端向节点发送命令时,接收命令的节点会计算出命令要处理的数据库键属于哪个槽,并检查这个槽是否指派给了自己:
- 如果键所在的槽正好指派给了当前节点,则该节点直接执行这个命令。
- 如果不是则当前节点会向客户端返回一个
MOVED错误,并携带正确节点的信息,指引客户端转向至正确的节点,并在此发送之前想要执行的命令。
重新分片的实现原理
Redis集群的重新分片操作是由Redis的集群管理软件redis-trib负责执行的,Redis提供了进行重新分片所需的所有命令,而redis-trib则通过向源节点和目标节点发送命令来进行重新分片操作。
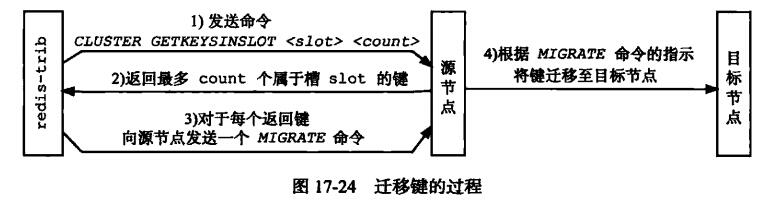
redis-trib对集群的单个槽slot进行重新分片的步骤如下:
- redis-trib对目标节点发送CLUSTER SETSLOT
slotIMPORTINGsource_id命令,让目标节点准备好从源节点导人( import)属于槽slot的键值对。 - redis-trib对源节点发送CLUSTER SETSLOT
slotMIGRATINGtarget_ id命令,让源节点准备好将属于槽slot的键值对迁移( migrate)至目标节点。 - redis-trib向源节点发送CLUSTER GETKEYSINSLOT
slotcount命令,获得最多count个属于槽slot的键值对的键名( key name )。 - 对于步骤3获得的每个键名,redis-trib都向源节点发送一个MIGRATE
target_ iptarget_ portkey_ name0timeout命令,将被选中的键原子地从源节点迁移至目标节点。 - 重复执行步骤3和步骤4,直到源节点保存的所有属于槽slot的键值对都被迁移至目标节点为止。每次迁移键的过程如图17-24所示。
- redis-trib向集群中的任意-一个节点发送CLUSTER SETSLOT
slotNODEtarget_id命令,将槽slot指派给目标节点,这一指派信息会通过消息发送至整个集群,最终集群中的所有节点都会知道槽slot已经指派给了目标节点。
ASK错误
在进行重新分片期间,源节点向目标节点迁移一个槽的过程中,可能会出现这样一种情况:属于被迁移槽的一部分键值对保存在源节点里面,而另一部分键值对则保存在目标节点里面。
当客户端向源节点发送一个与数据库键有关的命令,并且命令要处理的数据库键恰好就属于正在被迁移的槽时:
- 源节点会先在自己的数据库里面查找指定的键,如果找到的话,就直接执行客户端发送的命令。
- 相反地,如果源节点没能在自己的数据库里面找到指定的键,那么这个键有可能已经被迁移到了目标节点,源节点将向客户端返回一个ASK错误,指引客户端转向正在导人槽的目标节点,并再次发送之前想要执行的命令。
关系型数据库中的索引数据结构B+Tree
B+树的定义:
- 一个节点可以容纳多个值。
- 除非数据已经填满,否则不会增加新的层。也就是说,B树追求”层”越少越好。
- 子节点中的值,与父节点中的值,有严格的大小对应关系。一般来说,如果父节点有a个值,那么就有a+1个子节点。
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。
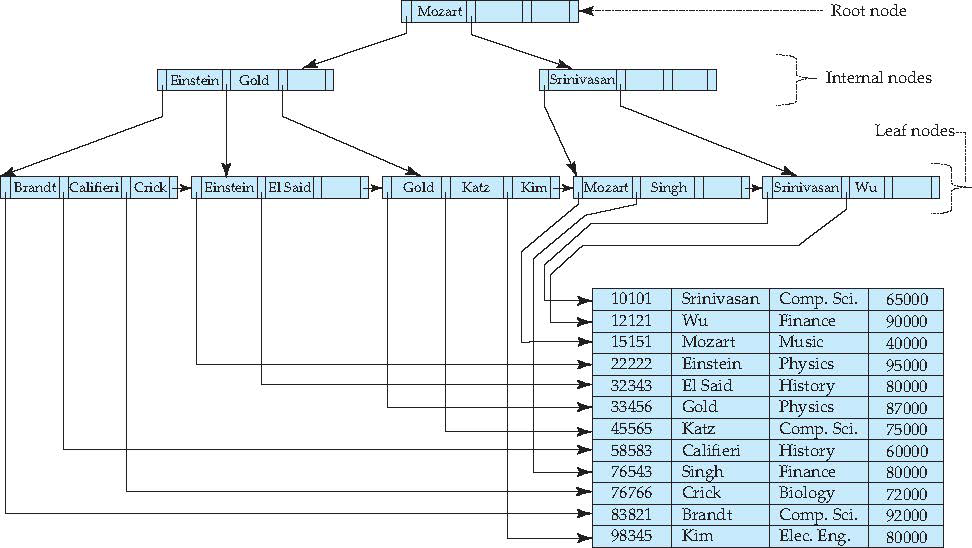
关系型数据库为什么要使用B+Tree作为索引,主要目的是为了减少磁盘的读取次数,B+树的每个节点存储了大量的索引信息(每个节点就相当于一个磁盘块), 所以查找一条数据记录只需要读取少量节点就可以找到数据的位置。
参考
本篇文章主要是读《redis设计与实现 第二版》这本书的读书笔记。打算好好看看数据库相关的知识,对数据库一直很陌生。