Apache Kafka是一个分布式流处理平台,他有三个关键能力:
- 发布和订阅消息流,类似于消息队列或者企业级消息系统。
- 高可用的持久存储消息流。
- 实时处理消息流
kafka的一些概念:
- kafka可以运行在分布于多个数据中心的集群上面。
- kafka通过
topic来区分不同类别的消息。 - 每条消息包含一个key、value和时间戳。
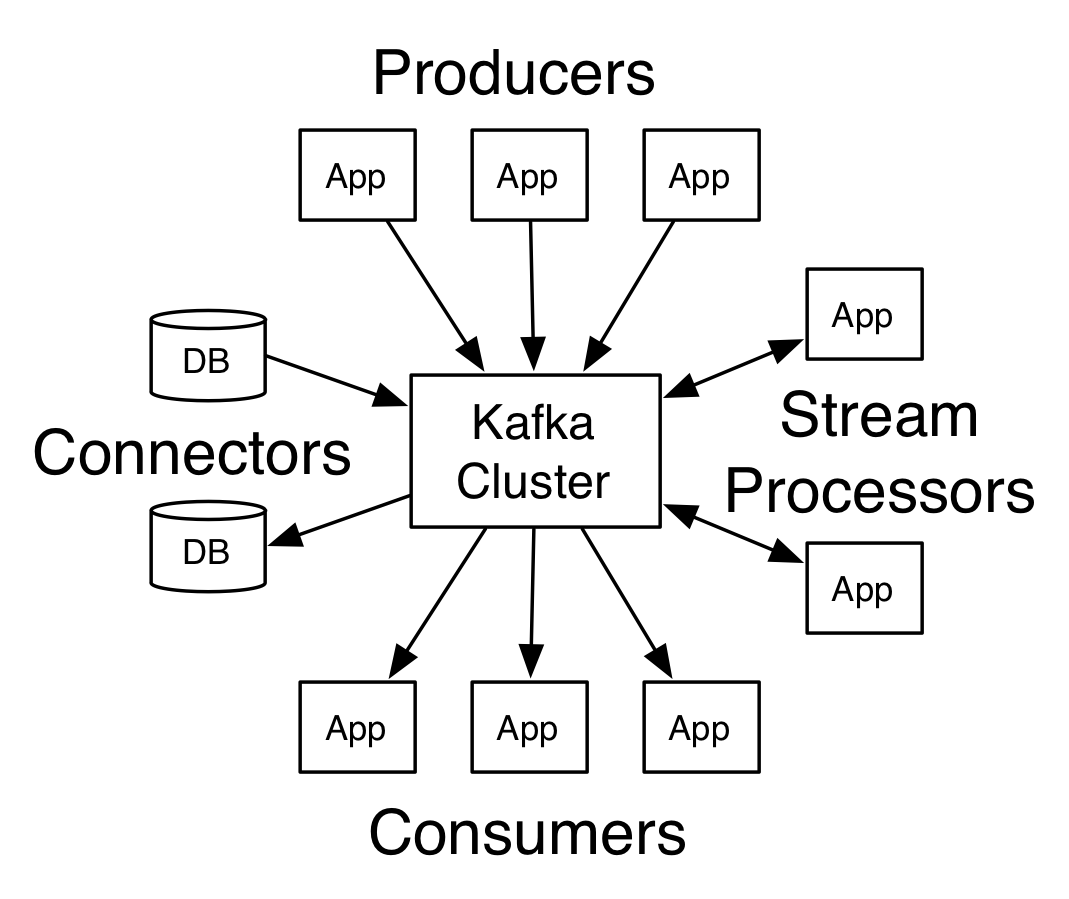
kafka的总体架构
应用(生产者)发送消息到kafka的一个节点上(broker),然后这个消息被其他叫做消费者的应用处理。
这个消息被存放在topic中,消费者通过订阅这个topic来接收新消息。
由于一个topic可能会非常大,出于性能和扩展性考虑,可以将topic再分成多个小的分区。
kafka保证一个分区中所有消息的存放顺序和消息进入的顺序一致。
一个特定的消息是通过偏移量(offset)来确定的,你可以把他看作为一个普通的数组索引或者序列号,分区中每进来一个新消息都会递增这个索引。
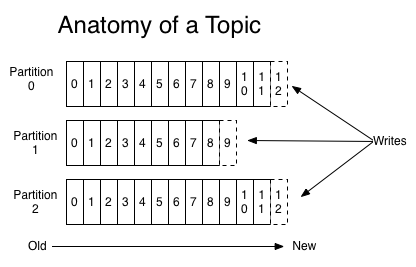
kafka不会因为某个消息被消费者读取了之后就删除这条消息,而是保存消息到达一定时间(可配置例如一天)或者当消息数量到达设置的值后才会删除消息。 消费者通过序列号在kafka中查询自己想要读取的消息,这意味着他们可以读取任意消息,从而实现重放和重复处理的功能。
kafka只保证在一个分区内的消息顺序性。如果你要求整个topic保持顺序性,可以将这个topic只分配一个分区,
为了保证单个分区内的消息顺序性,同一个消费组内每个分区只允许有一个消费进程。
数据读写
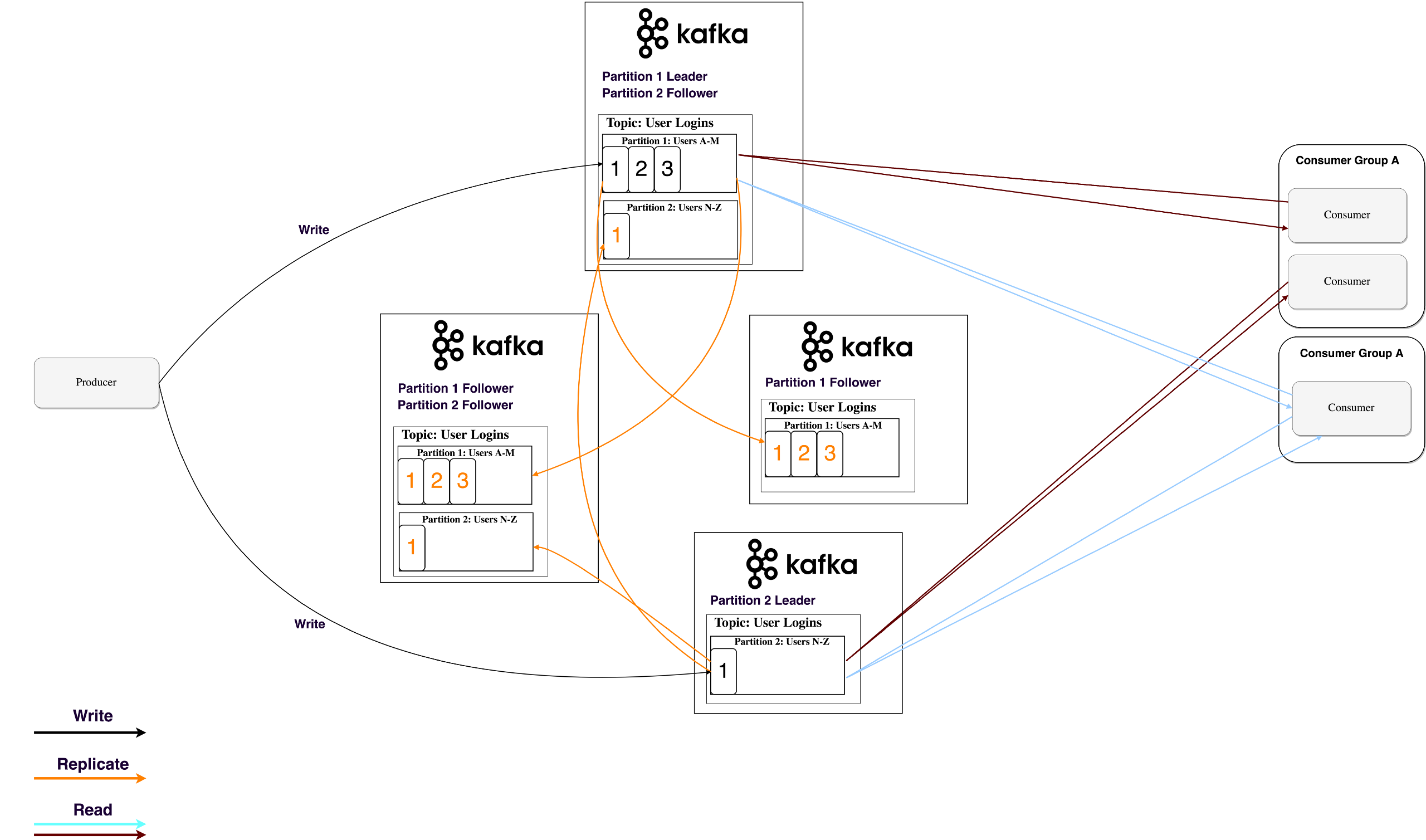
每个分区在多个broker上有备份,防止一个broker死机导致这个分区不可用。
任何时候都有一个broker上有一个主分区来接收外部读写请求。其他的备份分区叫做followers。
他们接收主发送的备份数据存储下来,并时刻等待当主挂掉之后被选举为主分区。
如下图:一个topic被分为两个partitions,每个partitions有三个备份分布在不同broker上,其中一个为主另外两个为从。
主节点接收外部读写请求,并将数据同步到从节点上。
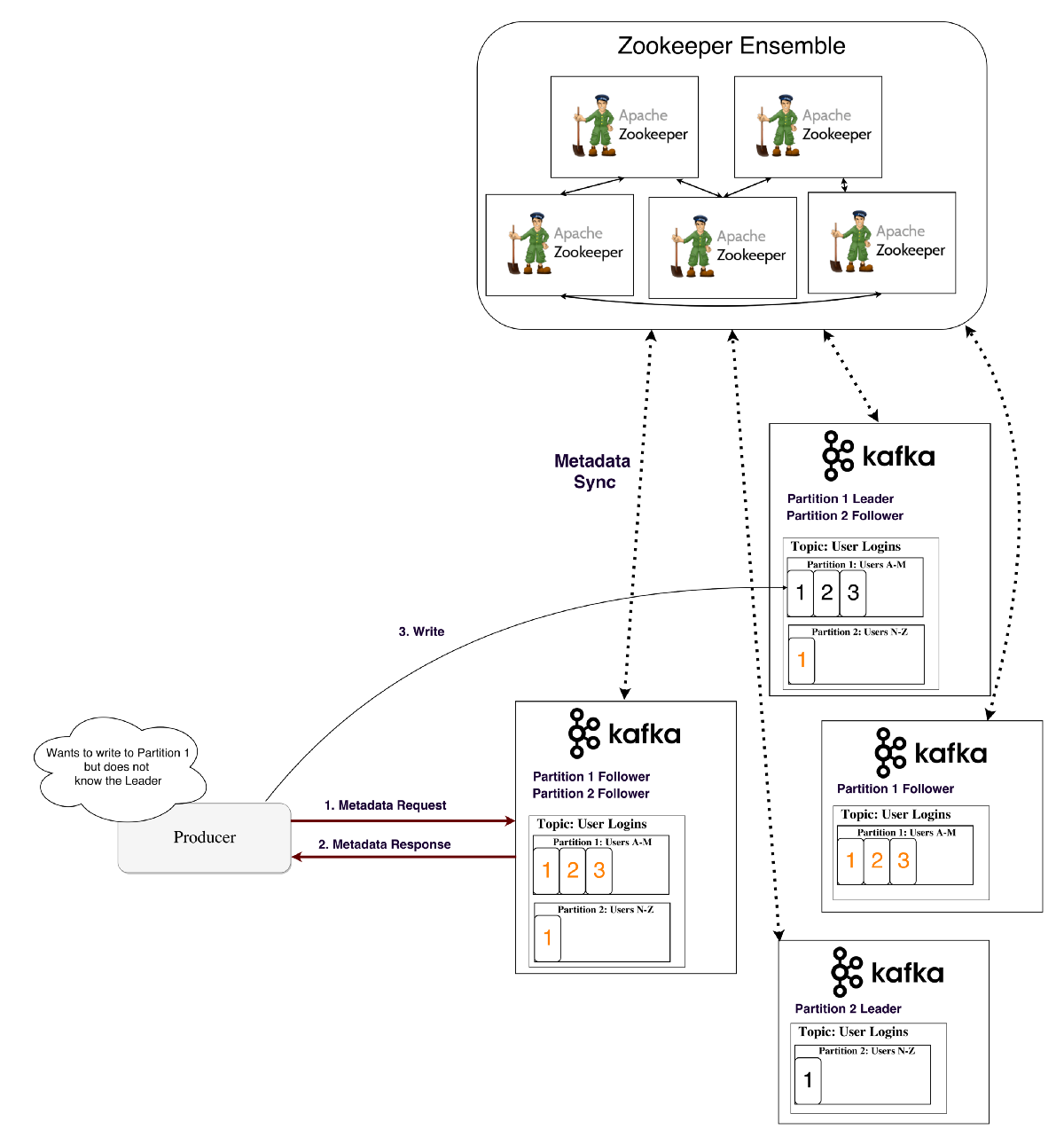
当生产者需要写数据时首先向kafka的一个broker节点发送metadata请求,broker节点会返回他要写的数据的主partitions是哪一个节点,
然后生产者再次发送写请求到该节点上。每个broker节点的信息是由Zookeeper来维护以及下发到各节点的。
生产者可以随机将消息发生到不同的分区,以达到负载均衡的效果。也可以通过hash的方式将相同ID的数据发送到相同的分区。 还可以将多个数据缓存起来,然后一次性批量发送出去,缓存的时间和数量都是可调节的。
kafka消费端通过拉取方式来消费消息,而某些其他系统使用推送方式消费消息,两种方式各有优劣。推送方式的缺点是很难控制消费速率, 因为是控制器主动分发消息,当生产速率大于消费速率时,可能导致消费者过载。而拉取方式可以很好的解决这个问题,消费者可以按需拉取消息。
拉取方式的另外一个好处是可以批量拉取消息的同时不会带来额外的延时,例如消费者一次想拉取10条消息,你有10条就返回10条,你没有10条也可以返回少于10条的消息,当使用推送方式时,如果每次都需要批量推送10条消息时则需要缓存消息带来延时,如果不缓存则会变成每条消息都会推送一次浪费带宽。
拉取方式的缺点是如果broker没有消息,消费端需要不断轮询查询是否有消息到来。为了缓解这种情况kafka可以阻塞拉取请求,直到有数据到来。
消息传递语义
消息队列一般提供三种不同的消息传递语义:
- 至多一次 - 消息可能丢失但是绝不会重复发送
- 至少一次 - 消息不会丢失但是可能重复发送
- 正好一次 - 这是最理想的状态,消息不会丢失也不会重复发送
kafka0.11.0.0之前的版本生产者没有收到消息被提交的回包确认时只能重复发送此消息,这可能导致broker侧的消息重复,所以这满足至少一次的语义。
从0.11.0.0版本开始kafka生产者支持幂等的消息传递,他保证重复发送的消息不会在broker中保存两份。为此broker需要给每个生产者分配一个ID,并使用与每个消息一起发送过来的序列号对重复消息进行删除。生产者也支持类似于事务的语义将消息发送到多个topic分区:即所有消息都成功写入,或者都不成功,这个功能主要用于支持正好一次的语义。
不是所有的场景都需要高可靠性,用户可以配置kafka的可靠性级别,可以配置为全异步发送消息,或者只需要主节点的回包确认。
从消费者的角度来看何时更新消费记录也是非常有讲究的,这里分为两种情况:
- 消费者读取消息,更新消费位置,然后处理消息。这种情况下如果消费者更新消费位置之后,处理消息之前挂了,则此条消息就不会再被处理了。这种情况满足
至多一次的语义。 - 消费者读取消息,处理消息,然后更新消费位置。这种情况下如果处理消息之后,更新消费位置之前挂了,则此条消息会被重复处理。这种情况满足
至少一次的语义。
那怎么实现正好一次的语义了?如果从一个topic队列中消费处理消息之后再投放到其他topic队列中,可以使用上面提到的0.11.0.0版本中的事务功能来实现。
如果消息处理后存放到其他系统中时,需要其他系统的配合。具体方法是将处理后的消息和消费位置信息一起存放到其他系统中,这样做保证了消息和更新消费位置信息的原子性。
参考
kafka官方文档
Thorough Introduction to Apache Kafka
Zookeeper的功能以及工作原理