- 前言
- Linux网络栈中的队列
- 驱动程序队列(又名:环形缓冲区)
- 协议栈中的巨型帧
- 饥饿和延迟
- Byte Queue Limits (BQL)
- Queuing Disciplines (QDisc)
- 传输层和规则队列之间的缓冲区
前言
本文是这篇文章的前半部分翻译:
Queueing in the Linux Network Stack
Linux网络栈中的队列
网络数据包队列是任何网络栈或设备的核心组成部分。他使得异步模块之间可以通信并且可以提高性能但是它的副作用是增加延迟。 本文的目标是解释IP数据包在Linux网络栈的什么地方进入队列,新的减少延迟的机制是怎样工作的例如BQL操作,以及怎样控制缓冲区来减少延迟。
下面这张图会贯穿整片文章,并且会做不同的修改来描述特定的概念。
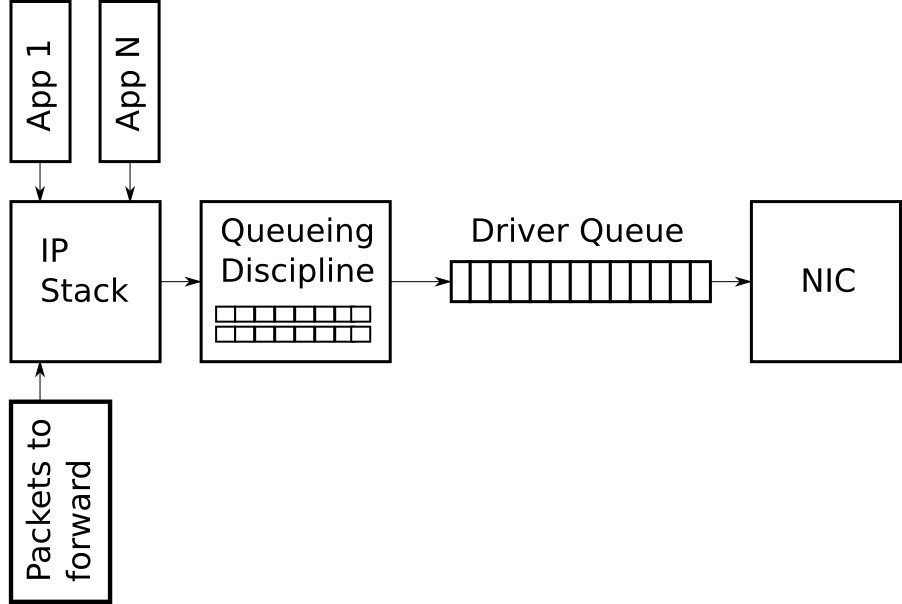 图1-Linux网络栈中数据包传送路径中高度简化版的数据包队列
图1-Linux网络栈中数据包传送路径中高度简化版的数据包队列
驱动程序队列(又名:环形缓冲区)
在IP协议栈和网卡(network interface controller - NIC)之间有一个驱动程序队列。这个队列是一个先进先出(FIFO)环形缓冲区 – 可以把他理解为一个固定大小的缓冲区。 这个驱动程序队列不包含数据包而是由一个个描述符组成,这些描述符指向一个被称作套接字内核缓冲区(SKB)的数据结构,SKB是内核用来表示网络数据包的结构体,他应用于整个协议栈。
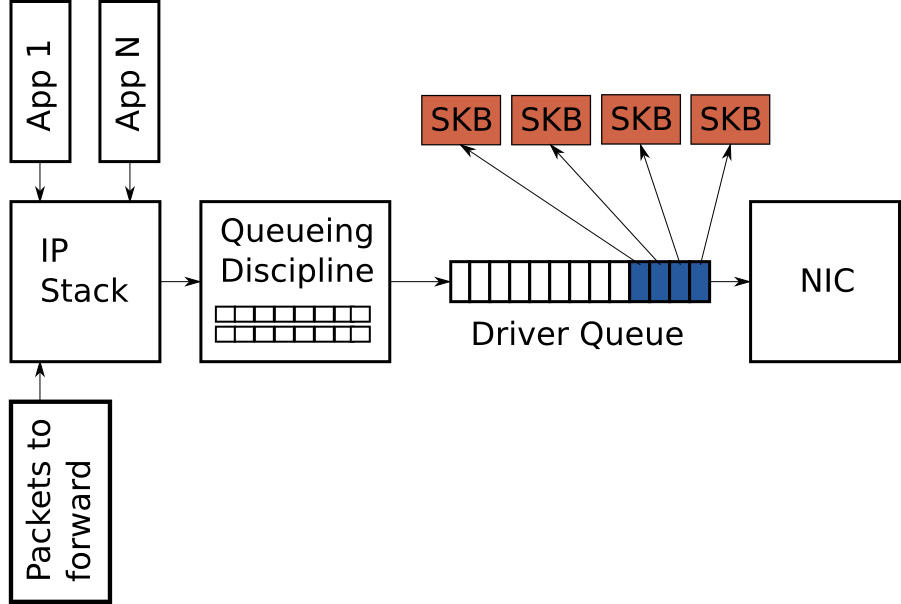
这个环形缓冲区的数据输入是IP协议栈中完整的IP数据包序列。这些数据包可能是本地产生的或者是当网络设备开启了IP路由功能时从一个网卡上接受的数据包要被路由到另一个网卡上。 数据包通过IP协议栈加载到环形缓冲区队列,然后硬件驱动通过网卡上的数据总线将数据包发送出去。
环形缓冲区存在的意义是确保无论系统什么时候需要发送数据,网卡都能够立即处理。也就是给了IP协议栈一个缓存区使得数据入队和硬件操作可以异步进行。 一种替代方法是当物理媒介准备好发送数据时网卡请求IP协议栈发送数据。但是请求不能瞬间完成导致浪费发送时机从而降低了吞吐量。 相反的做法是当IP数据包准备好后协议栈等待硬件直到可以发送数据,这种方法也不好因为IP协议栈在等待时不能做其他工作。
协议栈中的巨型帧
大多数网卡有一个固定的最大传送单元(MTU),他是硬件设备能够传送的最大数据帧。对于以太网设备来说默认的MTU是1500字节,但是有些以太网络支持9000字节的巨型帧。 在IP协议栈中MTU可以作为硬件设备能够传输的最大数据包大小的限制。例如,如果一个应用程序发送了2000个字节包给TCP套接字,IP协议栈需要创建两个IP数据包来接受数据使每个IP数据包的大小在1500字节以内。 当发送大量数据时由于MTU的限制会创建大量小型数据包然后通过环形缓冲区发送出去。
为了避免队列中出现过量的数据包,Linux内核采用了几种措施:TCP segmentation offload (TSO), UDP fragmentation offload (UFO) 和 generic segmentation offload (GSO)。
所有的这些优化允许IP协议栈创建大于MTU的数据包。在IPv4中可以创建最大为65536字节的数据包。由于TSO和UFO措施,使得网卡硬件自身必须将大型数据包分割为可以在物理设备上传输的小型数据包。
如果网卡不支持数据包分割,在进入环形缓冲区之前由GSO来完成这项工作。
前面讲到环形缓冲区存放着固定数量的描述符,这些描述符指向不同大小的数据包。由于TSO, UFO 和 GSO允许大型数据包,但是这种优化有一个负作用就是大量增加了排列在环形缓冲区中的字节数。 图3描述了这种情况:
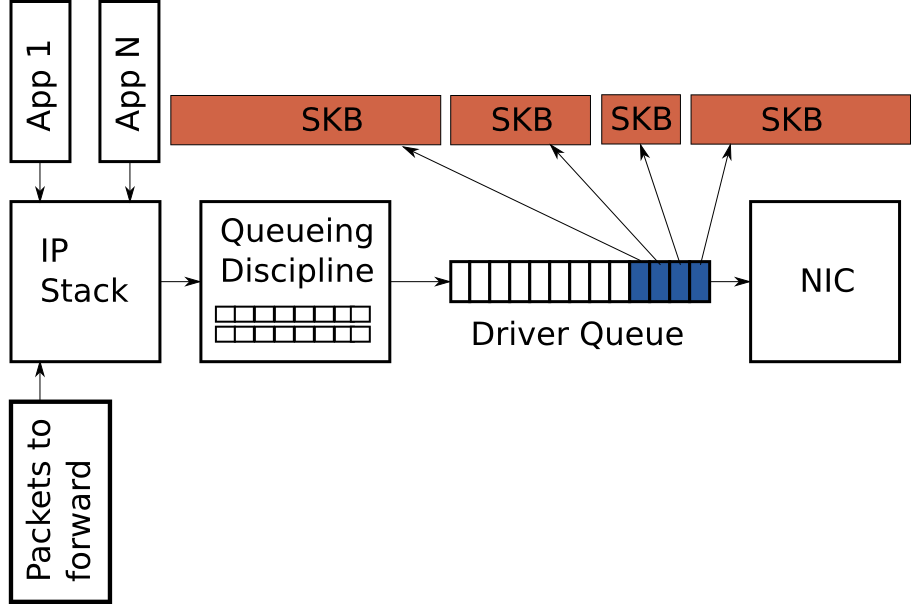
本文接下来关注的是数据包的传输路径,但是值得一提的是Linux也收到过类似于TSO, UFO 和 GSO这样的优化方法。这些优化措施也是致力于减少数据包的开销。
尤其是generic receive offload(GRO)它允许网卡驱动将接受到的数据包组合成一个大的数据包然后在传送给IP协议栈。当转发数据包时为了维持IP数据包端到端的特性,GRO需要还原成原始的数据包。
但是GRO有一个副作用,在转发数据包时将大型数据包分解为小型数据包给发送端时会导致瞬间有多个数据包进入队列,这种微型的爆发式数据包增长会对网络延迟造成负面影响。
饥饿和延迟
尽管IP协议栈和硬件之间的队列是必要的并且有益的,但是它会带来两个问题:饥饿和延迟。
如果网卡驱动被唤醒从队列中取出数据来发送但是队列是空的,硬件就会错失发送时机从而降低了系统的吞吐量,这种情况叫做饥饿。 注意当系统没有任何数据需要传送时空队列是正常的,不是饥饿。避免饥饿的难题在于IP协议栈填充数据到队列中和硬件驱动从队列中取出数据是异步的。 更糟糕的是填充数据和取出数据所需要的时间是变化的,这取决于系统的负载和其他外部条件例如网络接口的物理介质。 例如,当系统非常繁忙时IP协议栈只能得到非常少量的机会去往缓冲区中添加数据包,这就增加了硬件在队列中取数据时队列中没有数据的情况。 由于这个原因大的缓冲区有利于减少饥饿的可能性并确保高吞吐量。
虽然一个大队列对于繁忙系统维持高吞吐量是必要的,但是也有一个缺点就是增大延迟。
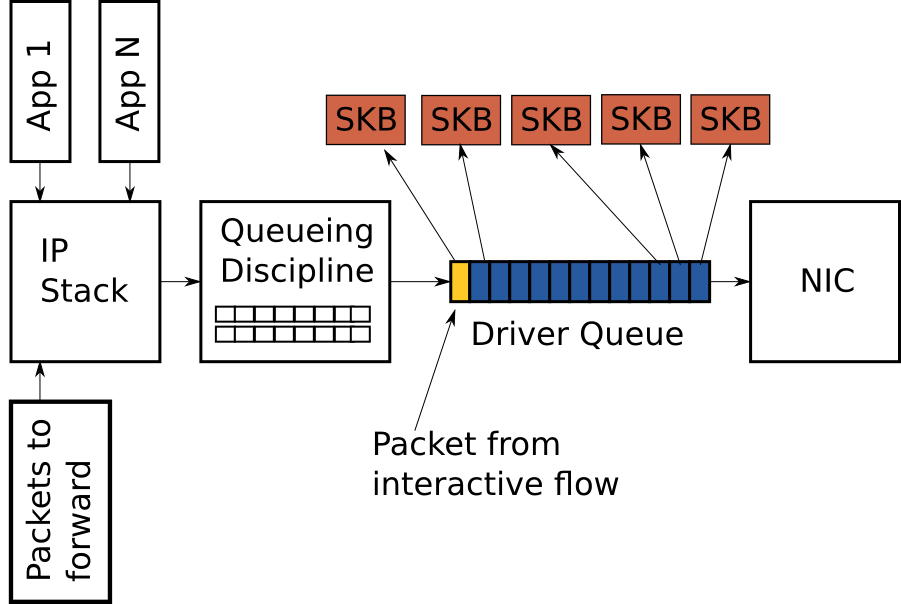
图4展示了环形缓冲区中填满了TCP数据包,蓝色部分是分散的数据包。队列的最后一个是VoIP或者某游戏的数据包(黄色的)。像VoIP或者游戏这样的交互应用程序通常会定时发送对延时非常敏感的短小数据包, 同时其他应用程序快速产生大量的大数据包。这种高频率的大数据包可以很快填满缓冲区导致交互程序的数据包被推迟发送。为了更好的描述这种情况做以下假设:
- 一个网络接口的最大传输速率是
5Mbit/s或者5000000bits/s。 - 每个大数据包的大小是
1500字节或者12000 bits。 - 每个交互应用程序的数据包是
500字节。 - 队列最多容纳128个描述符。
- 队列中有127个大数据包和1个交互应用程序的数据包在队列的最后面。
根据上面的假设,传输127个大数据包需要的时间是(127 * 12,000) / 5,000,000 = 0.304秒(304微妙这基本等于ping包的延迟时间)。
这个延迟时间对于交互应用程序来说是可以接受的但是这并不真实的延迟时间–这个时间仅仅表示从队列中发送完这些数据包。就像前面提到的如果TSO, UFO 或者 GSO被使能,这些数据包的大小可能大于1500字节。
这就会导致更大的延迟。
过大的数据包导致延迟增大的问题称为Bufferbloat。更多的细节请看Controlling Queue Delay 和Bufferbloat项目。
根据上面的讨论,选择一个合适大小的环形缓冲区是一个度的问题–不能太小会降低吞吐量,也不能太大会增大延迟时间。
Byte Queue Limits (BQL)
BQL是Linux内核中的新特性(内核版本大于3.3.0),用于自动调整驱动队列的大小。 它在当前的系统环境下通过计算避免饥饿发生的缓冲区最小值来允许和禁止数据包进入驱动队列。 前面提到过队列中的数据包越少,数据包的延迟越小。
需要注意的是BQL并不会改变驱动队列的实际大小,它只是计算出一个值来限制当前时间下进入队列中的最大数据量(单位是字节)。 任何超过这个限制的数据必须被驱动队列的上层缓存或者丢弃。
当数据包加入到驱动队列和数据包的发送完成时BQL开始运行。下面是BQL算法简化版本的伪代码,LIMIT的值是BQL计算出来的。
****
** After adding packets to the queue
****
if the number of queued bytes is over the current LIMIT value then
disable the queueing of more data to the driver queue
注意队列中的数据量可以大于LIMIT,因为数据包在检查LIMIT限制之前加入队列。
当吞吐量优化机制TSO、UFO或者GSO被使能时会有副作用,因为一次入队操作可能会加入一个很大的数据包。
如果你非常关注延迟你可以把这些机制禁用掉。本文的下面章节会介绍怎样禁用这些机制。
BQL运行的第二个阶段是当硬件完成数据包的发送时(伪代码如下):
****
** When the hardware has completed sending a batch of packets
** (Referred to as the end of an interval)
****
if the hardware was starved in the interval
increase LIMIT
else if the hardware was busy during the entire interval (not starved) and there are bytes to transmit
decrease LIMIT by the number of bytes not transmitted in the interval
if the number of queued bytes is less than LIMIT
enable the queueing of more data to the buffer
你可以看到BQL是根据检查设备是否饥饿来设置LIMIT的值。
一个现实中的例子可以帮助理解BQL的作用效果。我的一个服务器上的队列大小默认是256个描述符。
因为以太网的MTU是1500字节,所以驱动队列最大可以缓存256 * 1500 = 384000字节的数据
(TSO、GSO等被禁用否则这个值会更大)。但是BQL计算出来的限制值为3012字节,
你可以看到BQL限制了大量的数据进入队列。
BQL之所以使用字节而不像驱动队列和其他大多数包队列那样使用数据包,
是因为字节数比数据包可以更直接的反应当前时间物理设备需要发送的数据量。
BQL通过限制驱动队列中的数据量来减少延迟。这样也会有一个很大的副作用就是将数据包从简单的FIFO驱动
队列转移到更复杂的QDisc队列中去了。下一章节将会介绍Linux中的QDisc层。
Queuing Disciplines (QDisc)
驱动队列是一个简单的先进先出队列,它对待每个数据包都是公平的不会区分哪个包属于哪个流, 这种设计使得NIC驱动非常简单高效。需要注意的是很多高级以太网卡和大多数无线网卡支持多个发送队列 但是每个队列也都是FIFO队列,由驱动队列的上一层来决定使用哪个队列发送数据。
IP协议栈和驱动队列之间有一个规则队列(QDisc)层。该层实现了Linux内核的流量管理功能,包括流量分类,优先级排序和整流功能,QDisc层通过tc命令来配置。QDisc层中需要理解三个关键概念:队列、类和过滤。
QDisc是Linux抽像出来的流控队列,它比FIFO队列要复杂很多。它可以在不改变IP协议栈和NIC驱动的情况下实现
复杂队列管理功能。默认情况下每个网卡分配了一个pfifo_fast队列,他根据TOS字段的值实现了三个不同的优先级。
尽管pfifo_fast是默认队列,但是它不是最好的选择因为他不进行流识别而且队列非常长。
QDisc的第二个概念是类。某些QDisc可以分成不同的类来实现不同的流控功能。例如令牌桶(HTB)队列允许
用户配置500Kbps和300Kbps两类来分别进行流量控制。不是所有QDisc都支持多个类。
过滤(也叫做分类器)是将不同数据包分配到特定队列或类的机制。过滤器有很多种并且都非常复杂。 u32是最常见易用的过滤器。 关于流过滤的文档非常少但是你可以参考一下这个例子one of my QoS scripts。
关于QDiscs的更多细节可以查看LARTC HOWTO和tc命令的帮助文档。
传输层和规则队列之间的缓冲区
从上面的图中你会看到QDisc层之上就没有数据包队列了。这意味着Linux协议栈将数据包直接放在QDisc队列中
或者当QDisc队列已满时将数据包又返回存放到更上面的层中(例如:socket缓冲区中)。
一个明显的问题是当协议栈中有大量的数据包需要发送时会发生什么?这种情况可能发生在某个TCP连接中的发送窗口非常大或者某个糟糕的应用程序不加限制的发送大量UDP数据包。图4中已经说明了驱动队列中出现这种情况时的现象,单个高带宽的数据流或者高速率的数据包会消耗掉队列的所有缓存空间,导致数据包丢失并且大量增加其他数据流的延迟。更糟糕的是它会增加TCP数据包的延迟进而影响TCP的RTT和拥塞窗口的计算。因为Linux的默认队列pfifo_fast是单个队列(绝大多数数据流的TOS都标记为0),所以这种现象并不罕见。
从Linux3.6.0开始,Linux内核有一个新的特性叫做TCP Small Queues(TCP小队列)他致力于解决TCP的流量拥塞问题。
TCP Small Queues限制了每个TCP流进入QDisc和驱动队列的数据量。
这会带来一个有趣的额外作用,内核可以更早的将数据包返回给应用程序,从而使应用程序可以更加高效的调用socket发送数据。
到目前为止(2012-12-28)QDisc层仍然有可能被其他传输层协议中的单个数据流阻塞。
另一种解决办法是在QDisc层为每条数据流分别建立一个队列,这对传输层来说是透明的。QDiscs层中的Stochastic Fairness Queueing (SFQ)和 Fair Queueing with Controlled Delay (fq_codel)队列就是使用这种方法来解决流量拥塞问题的。