关于内存屏障的实验
当我们使用C或者C++编写lock-free(无锁)代码时,一定要特别注意内存读写顺序的正确性,不然会有意想不到的事情发生。
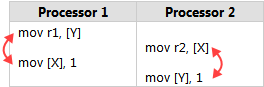
Intel在x86/64 Architecture Specification开发者手册中列举了几种这样的情况。下面是其中一个最简单的例子:假设内存中有两个整型变量x和y,初始值都为0,有两个CPU核心并行执行下面的代码:

不要在意示例中的代码是汇编语言,这是展示CPU指令执行顺序的最好方法。代码的逻辑是:每个CPU核心都往一个整型变量中存放数字1,然后加载另外一个变量到寄存器中。
此时不管哪个CPU核心先将数字1写入内存,我们可以很自然的推测寄存器r1=1,或者r2=1,或者两者都为1。但是Intel手册上说r1和r2都为0,也是一种可能的情况。
这就有点违背常理了!
出现这种情况的原因是Intel x86/64处理器和大多数处理器系列一样,支持按照一定规则对机器指令和内存之间的交互重新排序执行,只要不改变单线程的执行顺序就行。 特别是允许处理器延迟写内存,结果导致指令执行的顺序可以是下面这种情况:
我们来复现这种情况
手册上只说了这种情况可能发生,但是我们不能眼见为实。这也是为什么我要写一个示例程序来验证这种乱序执行的现象。你可以在这里下载测试代码。
该示例程序包含Win32和POSIX两个版本。它生成两个工作线程重复执行上面的任务,主线程用于同步他们的工作并检查每个变量的结果。下面是第一个工作线程的代码。
X、Y、r1和r2都是全局变量,使用POSIX信号来控制每次循环的开始和结束。
sem_t beginSema1;
sem_t endSema;
int X, Y;
int r1, r2;
void *thread1Func(void *param)
{
MersenneTwister random(1); // Initialize random number generator
for (;;) // Loop indefinitely
{
sem_wait(&beginSema1); // Wait for signal from main thread
while (random.integer() % 8 != 0) {} // Add a short, random delay
// ----- THE TRANSACTION! -----
X = 1;
asm volatile("" ::: "memory"); // Prevent compiler reordering
r1 = Y;
sem_post(&endSema); // Notify transaction complete
}
return NULL; // Never returns
};
每次循环前加了一个随机的延时操作,用于错开执行时间,促使这两个工作线程的指令交叉执行。
代码中的asm volatile("" ::: "memory")用于告诉GCC编译器生成机器指令时不要改变读、写内存的顺序,以防止编译器优化影响测试结果。
我们可以通过生成的汇编代码来确认指令的执行顺序。汇编代码如下:和我们期待的顺序是一样的,先赋值变量x为1,然后将y的值加载到eax寄存器中。
$ gcc -O2 -c -S -masm=intel ordering.cpp
$ cat ordering.s
...
mov DWORD PTR _X, 1
mov eax, DWORD PTR _Y
mov DWORD PTR _r1, eax
...
特别注意所有写共享内存发生在sem_post之前,所有读共享内存发生在sem_wait之后。在主线程和工作线程通信的过程中也需要遵循这种规则。
信号量使我们可以在不同平台上得到相同的语义,这意味着我们可以保证工作线程中x、y的初始值都为0,并且r1、r2中的结果也会准确传递给主线程。
换句话说信号量可以避免框架中的指令乱序执行导致的额外影响,让我们可以专注于实验本身。
int main()
{
// Initialize the semaphores
sem_init(&beginSema1, 0, 0);
sem_init(&beginSema2, 0, 0);
sem_init(&endSema, 0, 0);
// Spawn the threads
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, thread1Func, NULL);
pthread_create(&thread2, NULL, thread2Func, NULL);
// Repeat the experiment ad infinitum
int detected = 0;
for (int iterations = 1; ; iterations++)
{
// Reset X and Y
X = 0;
Y = 0;
// Signal both threads
sem_post(&beginSema1);
sem_post(&beginSema2);
// Wait for both threads
sem_wait(&endSema);
sem_wait(&endSema);
// Check if there was a simultaneous reorder
if (r1 == 0 && r2 == 0)
{
detected++;
printf("%d reorders detected after %d iterations\n", detected, iterations);
}
}
return 0; // Never returns
}
下面展示的是Cygwin在Intel Xeon W3520处理器上运行的结果:
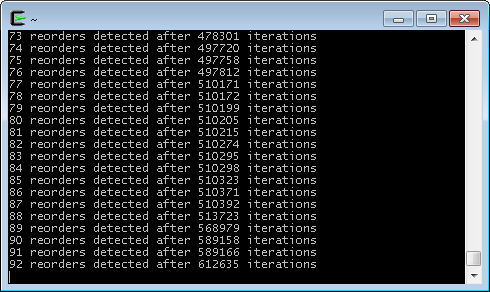
从上面的结果中可以看到,大约每6600次循环就会出现一次乱序执行的问题。当我在Ubuntu Core 2 Duo E6300处理器上测试时出现的概率更低。 可以想象这种Bug是多么难以发现。
译者测试的环境是Ubuntu Intel(R) Core(TM) i7-6700处理器vm虚拟机上的运行结果:
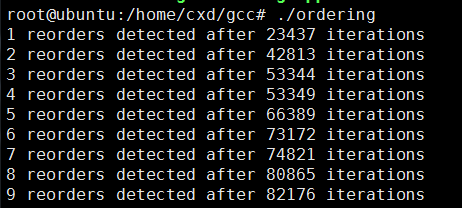
那该怎么解决这个问题了?至少有两种方法可以解决它。第一种方法是设置工作线程的亲和性,使两个线程运行在同一个CPU核心上。 这种方法不具备可移植性,但是在Linux上面我们可以这样设置线程的亲和性:
cpu_set_t cpus;
CPU_ZERO(&cpus);
CPU_SET(0, &cpus);
pthread_setaffinity_np(thread1, sizeof(cpu_set_t), &cpus);
pthread_setaffinity_np(thread2, sizeof(cpu_set_t), &cpus);
这样设置之后,问题就解决了。这是因为单个处理器上不可能出现失序的情况,即使线程在任何时候被抢占和调度。当然将两个线程锁定在一个CPU核心上运行, 就浪费了另一个CPU的资源。
使用内存屏障来解决乱序问题
另外一种解决方法是使用CPU指令来阻止读写内存的顺序发送改变。在x86/64处理器中有几个指令可以做这件事,mfence指令是一个完全的内存屏障,
不管是读内存还是写内存它都会防止乱序执行。(译者注:lfence读内存屏障,sfence写内存屏障)在GCC中我们可以这样使用它:
for (;;) // Loop indefinitely
{
sem_wait(&beginSema1); // Wait for signal from main thread
while (random.integer() % 8 != 0) {} // Add a short, random delay
// ----- THE TRANSACTION! -----
X = 1;
asm volatile("mfence" ::: "memory"); // Prevent memory reordering
r1 = Y;
sem_post(&endSema); // Notify transaction complete
}
你可以再次通过查看汇编代码来确认mfence指令:
...
mov DWORD PTR _X, 1
mfence
mov eax, DWORD PTR _Y
mov DWORD PTR _r1, eax
...
这样修改之后,就不会再有乱序执行的问题了,并且我们仍然可以将两个线程运行在不同的CPU核心上。
不同平台上的相似指令
有趣的是x86/64处理器中不只mfence这一个完全的内存屏障指令。这些处理器中的任何locked指令,例如xchg也是一种完全的内存屏障 – 只要你不使用SSE指令集和
write-combined memory。事实上,当你使用Microsoft C++编译器中的内部函数MemoryBarrier时,至少在Visual Studio 2008中会生成xchg指令。
mfence是x86/64处理特有的指令,如果你想让代码具备更好的可移植性,你可以使用一个宏来包装它。Linux内核中已经有这样的宏smp_mb以及其相关的宏smp_rmb和smp_wmb,并且在不同的架构下,这个宏的实现也是不同的。例如在PowerPC中smp_mb使用的是sync指令。
不同的处理器族,都会有自己特有的内存屏障指令,编译器对每种处理器族提供不同的宏实现,因此对于跨平台项目还需要专门的适配层,这对于无锁编程一点也不友好。
这也是为什么C++11会引入atomic library,试图提供标准化接口使无锁编程变得更加简单。
本实验的完整代码
#include <pthread.h>
#include <semaphore.h>
#include <stdio.h>
// Set either of these to 1 to prevent CPU reordering
#define USE_CPU_FENCE 0
#define USE_SINGLE_HW_THREAD 0 // Supported on Linux, but not Cygwin or PS3
#if USE_SINGLE_HW_THREAD
#include <sched.h>
#endif
//-------------------------------------
// MersenneTwister
// A thread-safe random number generator with good randomness
// in a small number of instructions. We'll use it to introduce
// random timing delays.
//-------------------------------------
#define MT_IA 397
#define MT_LEN 624
class MersenneTwister
{
unsigned int m_buffer[MT_LEN];
int m_index;
public:
MersenneTwister(unsigned int seed);
// Declare noinline so that the function call acts as a compiler barrier:
unsigned int integer() __attribute__((noinline));
};
MersenneTwister::MersenneTwister(unsigned int seed)
{
// Initialize by filling with the seed, then iterating
// the algorithm a bunch of times to shuffle things up.
for (int i = 0; i < MT_LEN; i++)
m_buffer[i] = seed;
m_index = 0;
for (int i = 0; i < MT_LEN * 100; i++)
integer();
}
unsigned int MersenneTwister::integer()
{
// Indices
int i = m_index;
int i2 = m_index + 1; if (i2 >= MT_LEN) i2 = 0; // wrap-around
int j = m_index + MT_IA; if (j >= MT_LEN) j -= MT_LEN; // wrap-around
// Twist
unsigned int s = (m_buffer[i] & 0x80000000) | (m_buffer[i2] & 0x7fffffff);
unsigned int r = m_buffer[j] ^ (s >> 1) ^ ((s & 1) * 0x9908B0DF);
m_buffer[m_index] = r;
m_index = i2;
// Swizzle
r ^= (r >> 11);
r ^= (r << 7) & 0x9d2c5680UL;
r ^= (r << 15) & 0xefc60000UL;
r ^= (r >> 18);
return r;
}
//-------------------------------------
// Main program, as decribed in the post
//-------------------------------------
sem_t beginSema1;
sem_t beginSema2;
sem_t endSema;
int X, Y;
int r1, r2;
void *thread1Func(void *param)
{
MersenneTwister random(1);
for (;;)
{
sem_wait(&beginSema1); // Wait for signal
while (random.integer() % 8 != 0) {} // Random delay
// ----- THE TRANSACTION! -----
X = 1;
#if USE_CPU_FENCE
asm volatile("mfence" ::: "memory"); // Prevent CPU reordering
#else
asm volatile("" ::: "memory"); // Prevent compiler reordering
#endif
r1 = Y;
sem_post(&endSema); // Notify transaction complete
}
return NULL; // Never returns
};
void *thread2Func(void *param)
{
MersenneTwister random(2);
for (;;)
{
sem_wait(&beginSema2); // Wait for signal
while (random.integer() % 8 != 0) {} // Random delay
// ----- THE TRANSACTION! -----
Y = 1;
#if USE_CPU_FENCE
asm volatile("mfence" ::: "memory"); // Prevent CPU reordering
#else
asm volatile("" ::: "memory"); // Prevent compiler reordering
#endif
r2 = X;
sem_post(&endSema); // Notify transaction complete
}
return NULL; // Never returns
};
int main()
{
// Initialize the semaphores
sem_init(&beginSema1, 0, 0);
sem_init(&beginSema2, 0, 0);
sem_init(&endSema, 0, 0);
// Spawn the threads
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, thread1Func, NULL);
pthread_create(&thread2, NULL, thread2Func, NULL);
#if USE_SINGLE_HW_THREAD
// Force thread affinities to the same cpu core.
cpu_set_t cpus;
CPU_ZERO(&cpus);
CPU_SET(0, &cpus);
pthread_setaffinity_np(thread1, sizeof(cpu_set_t), &cpus);
pthread_setaffinity_np(thread2, sizeof(cpu_set_t), &cpus);
#endif
// Repeat the experiment ad infinitum
int detected = 0;
for (int iterations = 1; ; iterations++)
{
// Reset X and Y
X = 0;
Y = 0;
// Signal both threads
sem_post(&beginSema1);
sem_post(&beginSema2);
// Wait for both threads
sem_wait(&endSema);
sem_wait(&endSema);
// Check if there was a simultaneous reorder
if (r1 == 0 && r2 == 0)
{
detected++;
printf("%d reorders detected after %d iterations\n", detected, iterations);
}
}
return 0; // Never returns
}
编译:
gcc -o ordering -O2 ordering.cpp -lpthread
译者注
这边文章是翻译自Memory Reordering Caught in the Act。最近想了解一下无锁队列的实现原理,遇到的第一个困难就是这个内存屏障,大多数文章中只是介绍了一下内存屏障的概念,对于我这种小白来说还是不能真正理解什么是内存屏障,然后在网上看到这篇文章,他通过写代码来测试内存屏障,觉得很不错遂决定翻译下来,顺便好好理解一下这篇文章。