- 收集器简介
- Mark Setup - STW
- Marking - Concurrent
- Mark Termination - STW
- Sweeping - Concurrent
- GC Percentage
- GC Trace
- 三色标记
- 参考
收集器简介
一次垃圾回收可以分为三个阶段。其中的两个阶段会造成STW(Stop The World)延时,另外一个阶段会降低程序吞吐量。 这三个阶段分别是:
- Mark Setup - STW
- Marking - Concurrent
- Mark Termination - STW
下面来具体分析每一个阶段。
Mark Setup - STW
当开始垃圾回收时,第一步必须先打开写屏障。打开写屏障的目的是防止gc和go协程并发运行时导致内存数据被写乱。 为了开启写屏障需要暂停所有正在运行的协程,这个动作非常快一般在10到30微妙之内完成。
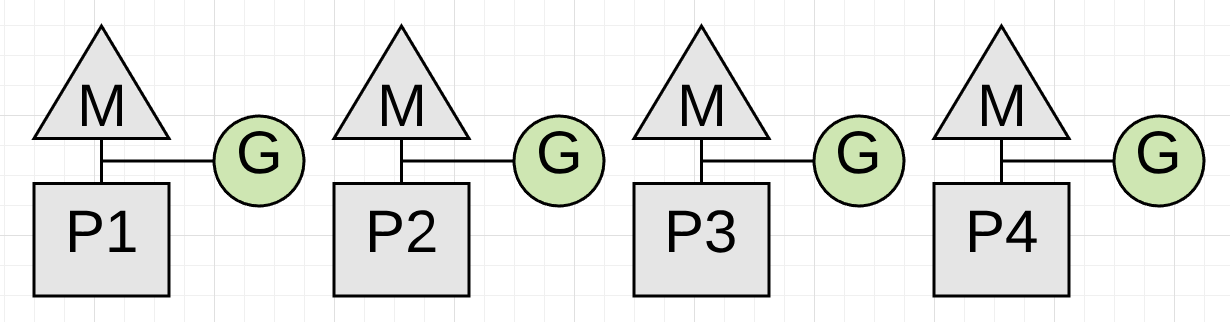
图1展示了4个正在运行的协程,当开始gc时4个协程必须都暂停运行。让协程停止的唯一办法就是gc等待协程发生函数调用,函数调用时可以保证协程在一个安全状态下被停止。 如果其中有一个协程不发生协程调用怎么办?
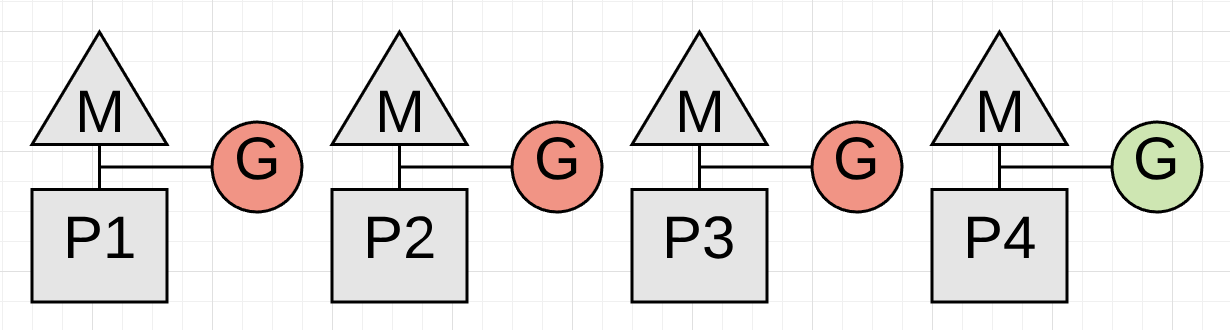
图2中展示了这个问题。gc在等待协程发生函数调用但是运行在P4上的协程一直没有发生函数调用,因为它在执行一个循环任务。
func add(numbers []int) int {
var v int
for _, n := range numbers {
v += n
}
return v
}
上面是P4上的协程正在运行的代码,由于切片的大小未知,此协程会在一个不可预知的时间段内无法被暂停,这会导致gc无法继续执行。
更加糟糕的是此时其他P上的协程无法继续运行,因为他们已经被gc暂停,所以在一个合理的时间段内发生函数调用是非常重要的。
注意:这个问题已经在go 1.14版本中通过引入抢占技术被解决。
Marking - Concurrent
一旦写屏障被打开,gc开始进入下一个阶段 - 标记阶段。这个阶段中gc做的第一件事是占用CPU 25%的计算资源用于标记。 gc也是使用协程来进行收集工作的,所以也需要在P和M上运行。这意味着需要在4个P中选择一个P完全共gc使用。
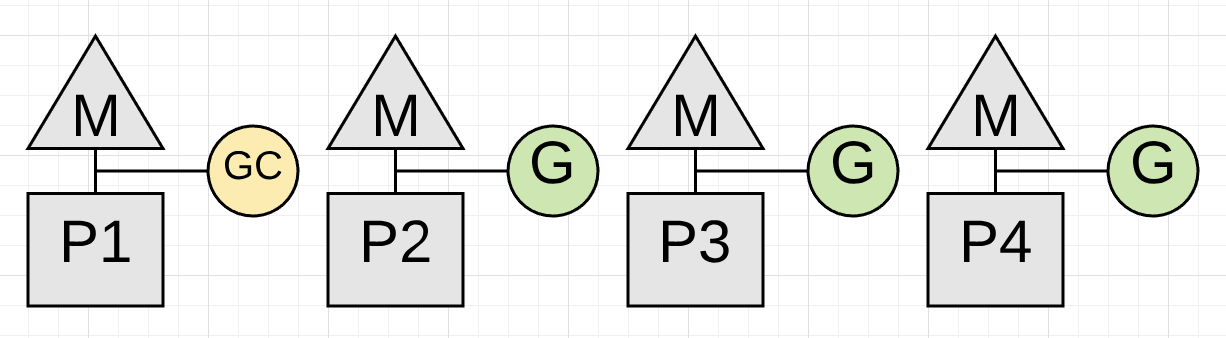
图3中gc占用了P1,此时gc可以开始进行第二阶段的工作。标记阶段主要是标记堆内存中还在被使用的内存块, 首先会检查当前所有协程的堆栈以已找到指向堆内存的根指针,然后需要通过根指针遍历整个堆内存中被引用的内存块。 因为标记工作在P1上运行,所以P2、P3和P4上的协程可以继续执行,这意味着gc的影响已最小化到当前CPU利用率的25%。
当然这不是故事的结局,如果在gc标记工作完成之前内存使用量已经达到了最大限制怎么办? 如果其他正在运行的协程使用内存的速度大于收集内存协程的标记速度怎么办? 这种情况下只能减少内存的分配,特别是那些大量分配内存的协程。
如果gc检测到需要减少内存分配,它会将其他协程招募过来协助标记工作。这种被称为MA(Mark Assist), 其他协程被设置为MA的时间长度和它使用内存的量成正比。
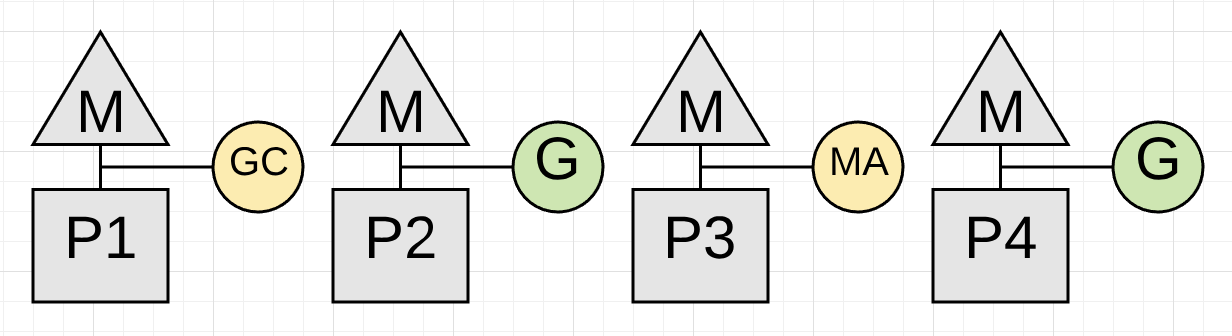
图4展示了P3上的协程被设置为MA用于协助标记工作。在内存分配频繁的应用程序中gc的时候可能会看到大多数正在运行的协程都会执行少量的MA任务。
gc的其中一个目标是减少使用MA,如果一次gc过程中需要大量MA,那么下次gc会提前执行。这么做是为了在下次gc过程中减少使用MA。
Mark Termination - STW
一旦标记阶段完成,gc开始进入下一阶段 - 标记终止。这个阶段的工作是关闭写屏障,执行各种清理任务然后计算下一次gc的启动时机。 标记开始阶段遇到的因为紧密循环而导致开启写屏障的时延变大,在关闭写屏障时也可能遇到。
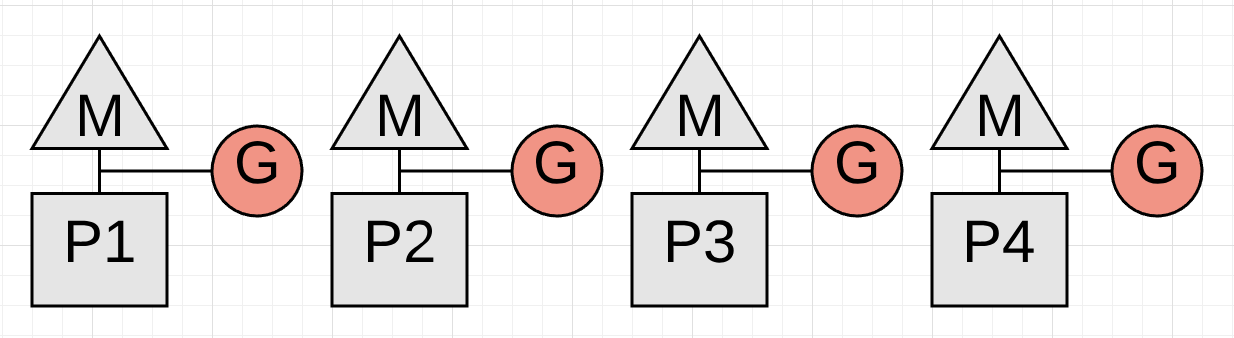
图5展示了在标记终止阶段暂停了所有协程,这个暂停时延平均在60到90微秒。这个阶段其实可以不需要STW,但是会增加代码复杂度不值得。
一旦gc完成,所有P就可以继续全力执行应用协程了,图6展示了gc完成后所有P再次执行应用协程,恢复到gc开始之前的状态。
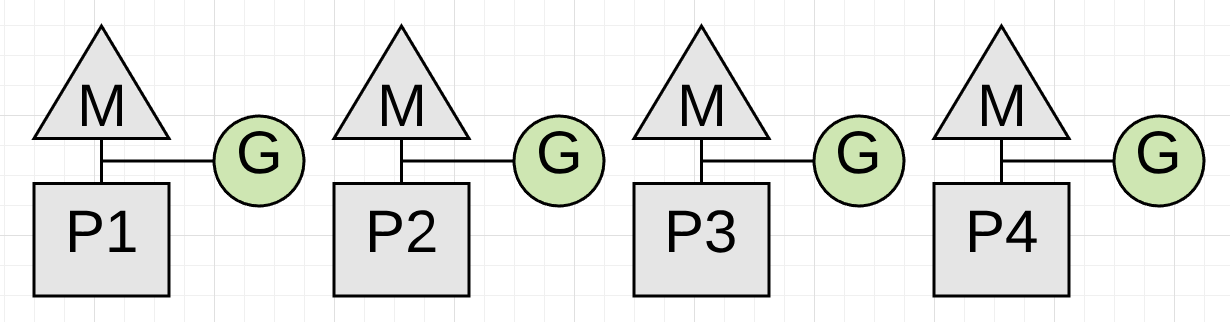
Sweeping - Concurrent
gc完成后还有一个工作叫做Sweeping(清扫),主要是清理gc过程中被标记为需要被回收的垃圾内存, 它发生在应用协程需要分配新内存的时候,内存清理的延时被加在了分配内存的延时中和gc没有关系。
下图是在一台有12个硬件线程运行协程的机器上的gc示例:
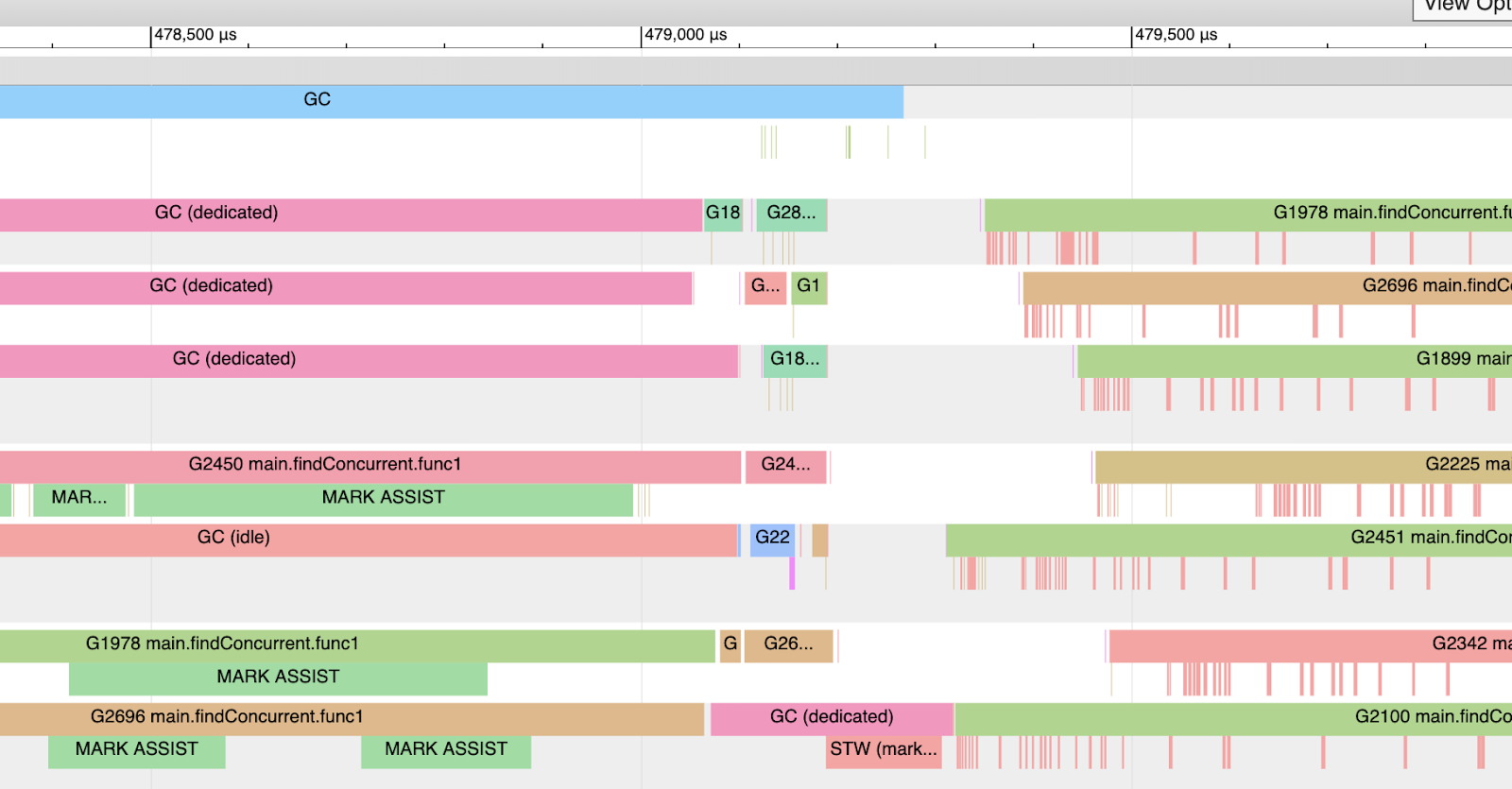
图7中最上面的蓝色彩条表示一个gc周期,期间在12个P中选取了3个P供gc使用。可以看到2450,1978和2696这三个协程也被设置为MA,辅助gc标记。 在gc的最后阶段只使用了一个P用于执行最后阶段的任务。
gc结束之后,应用程序恢复全速运行,但是你会看到协程下面会有很多粉红色的彩条。
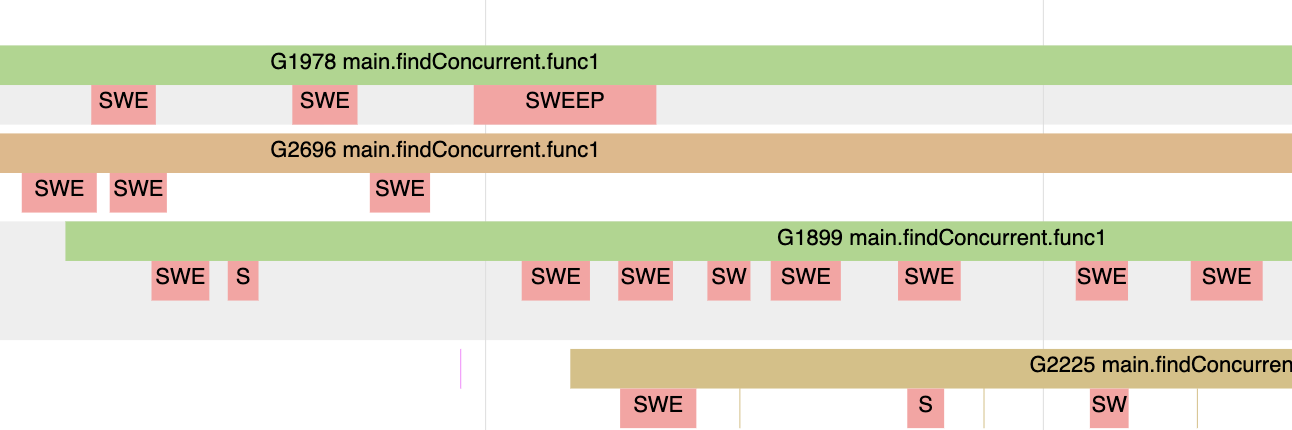
图8展示了粉红色的彩条表示协程正在执行Sweeping(清理)任务,当协程需要在堆内存中分配新内存时会执行此任务。
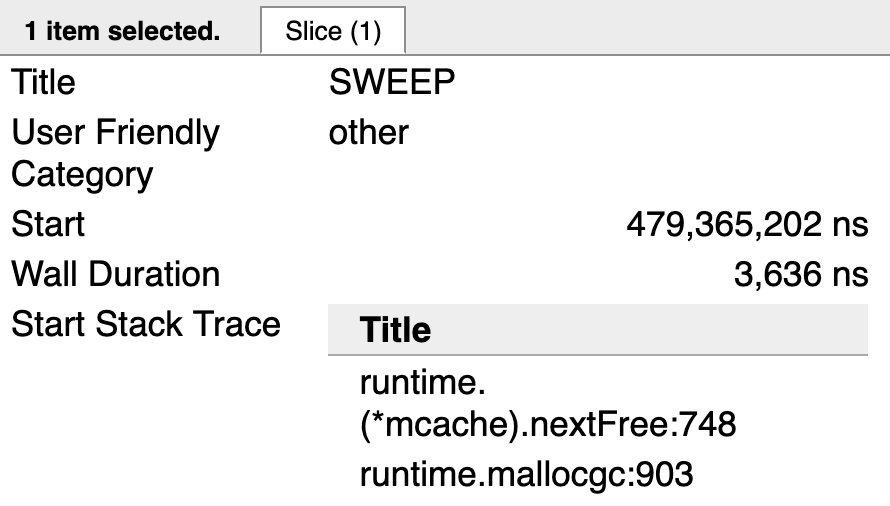
图9显示了协程在执行Sweeping(清理)任务时堆栈中的函数调用情况,runtime.mallocgc函数用于在堆内存中分配新内存,
runtime.(*mcache).nextFree就是执行Sweeping(清理)任务的函数。一旦没有垃圾内存需要回收时,nextFree将不会再被调用。
GC Percentage
上面讨论gc的行为都是在gc运行的周期内,而GC Percentage(gc百分比?)配置项决定了gc何时执行。
一般默认设置为100,他的意思是在进行下一次gc前可以使用多少新内存相对于已经使用内存的比例。
例如一次gc完成后还有2MB内存不能被回收还在使用中,百分比设置为100,则下次触发gc的时刻是使用了4MB内存的时候。
当然不是完全遵守这个配置规则,gc的启动时刻还受其他因素的影响。
GC Trace
在运行go程序之前在GODEBUG环境变量中加入gctrace=1选项可以打开gc跟踪信息,每次发生gc时会打印一条跟踪信息到stderr。
GODEBUG=gctrace=1 ./app
gc 1405 @6.068s 11%: 0.058+1.2+0.083 ms clock, 0.70+2.5/1.5/0+0.99 ms cpu, 7->11->6 MB, 10 MB goal, 12 P
gc 1406 @6.070s 11%: 0.051+1.8+0.076 ms clock, 0.61+2.0/2.5/0+0.91 ms cpu, 8->11->6 MB, 13 MB goal, 12 P
gc 1407 @6.073s 11%: 0.052+1.8+0.20 ms clock, 0.62+1.5/2.2/0+2.4 ms cpu, 8->14->8 MB, 13 MB goal, 12 P
上表中展示了怎样使用GODEBUG环境变量来打印gc信息,另外还展示了程序运行过程中打印的三条gc跟踪信息。
下面来介绍跟踪信息里每个值的含义。
gc 1405 @6.068s 11%: 0.058+1.2+0.083 ms clock, 0.70+2.5/1.5/0+0.99 ms cpu, 7->11->6 MB, 10 MB goal, 12 P
// General
gc 1405 : 程序从开始运行时的第1405次gc
@6.068s : 程序的运行时长
11% : 到目前为止,gc总共消耗了CPU 11%的利用率
// Wall-Clock 本次gc的三个阶段的处理时长
0.058ms : STW : Mark Start - Write Barrier on
1.2ms : Concurrent : Marking
0.083ms : STW : Mark Termination - Write Barrier off and clean up
// CPU Time 本次gc的三个阶段使用CPU的时长
0.70ms : STW : Mark Start
2.5ms : Concurrent : Mark - Assist Time (GC performed in line with allocation)
1.5ms : Concurrent : Mark - Background GC time
0ms : Concurrent : Mark - Idle GC time
0.99ms : STW : Mark Term
// Memory
7MB : GC开始前的内存使用量
11MB : GC完成后内存的使用量
6MB : GC完成后被标记为还在使用的内存量
10MB : GC完成后的目标内存使用量
// Threads
12P : 用于运行协程的线程数
三色标记
- 有黑白灰三个集合,初始时所有对象都是白色
- 从Root对象(栈引用的对象和全局对象)开始标记,将所有可达对象标记为灰色
- 从灰色对象集合取出对象,将其引用的对象标记为灰色,放入灰色集合,并将自己标记为黑色
- 重复第三步,直到灰色集合为空,即所有可达对象都被标记
- 标记结束后,不可达的白色对象即为垃圾。对内存进行迭代清扫,回收白色对象
- 重置GC状态
参考
本篇文章翻译自下面这篇文章,可以帮助了解go的整个gc流程,但是又不拘泥于gc的细节。