- Cassandra整体架构
- Cassandra的数据模型
- Cassandra数据备份
- Cassandra写操作
- SSTables存储格式
- Cassandra读操作
- Node之间的通信协议Gossip
- 参考:
Cassandra整体架构
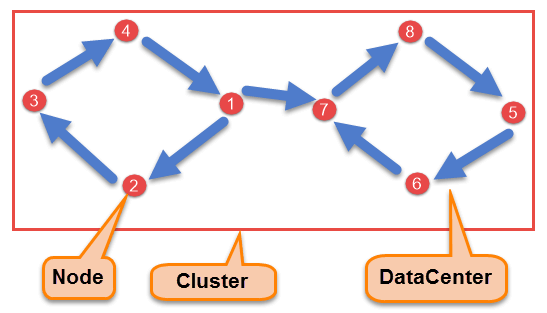
Cassandra主要有下面这些组件组成:
- Node
Node用于存放数据,是Cassandra的基础单元; - Data Center
多个Node集合组成一个Data Center; - Cluster
多个Data Center形成一个Cluster; - Commit Log
每次写操作都会记录到Commit Log中,用于数据恢复 - Mem-table
Commit Log记录完之后,会将数据写到Mem-table中,Mem-table是一个内存缓冲区。 - SSTables
当Mem-table中的数据到达一定量之后会将数据写入到磁盘中的SSTables文件集合中。
Cassandra的数据模型
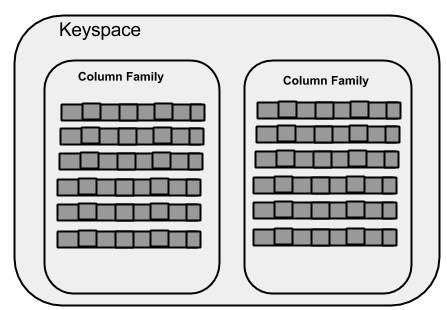
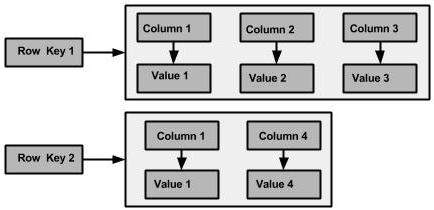
Keyspace是Cassandra中最外层的数容器,一个Keyspace包含多个Column families,一个Column families中包含多个row,一个row中包含多个column,
column是Cassandra最基本的数据结构,一个column中包含三个值:键、值和时间戳。
Cassandra数据备份
Cassandra有两种备份策略:
- SimpleStrategy
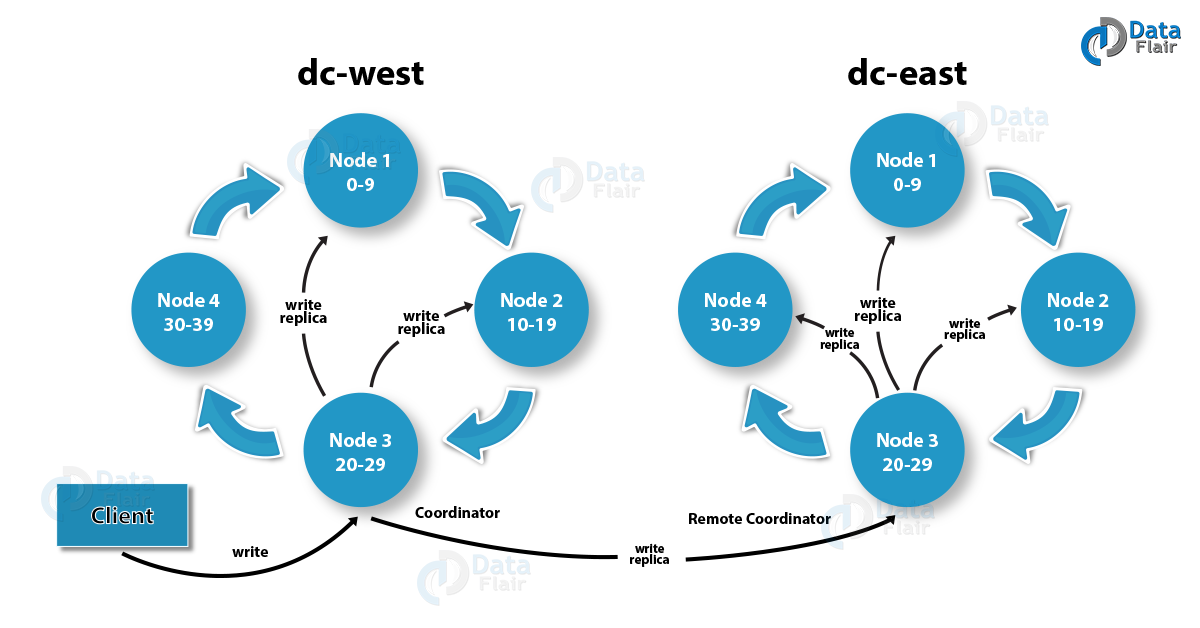
用于只部署了一个数据中心的场景,首先由一致性哈希算法计算得到数据块的存放位置,然后根据配置的备份数量,顺时针查找Node,将剩余的备份依次存入查找到的Node中。 - NetworkTopologyStrategy
用于部署了多个数据中心的场景,可以单独设置每个数据中心的备份数量,数据中心内采用顺时针查找机架,将剩余的备份依次存入查找到的机架中(一个机架中可以有多个Node,此策略可以保证数据备份不在同一个机架中)。
Cassandra写操作
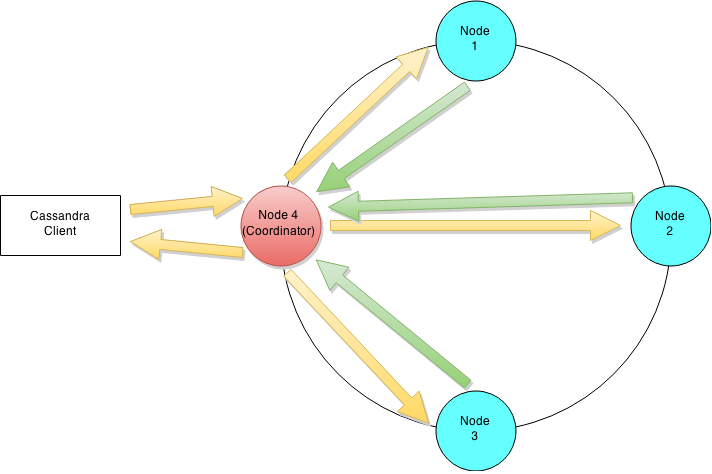
因为Cassandra是无主结构,所以客户端可以连接到任何一个Node上,被连接的这个Node称为coordinator,coordinator负责处理此客户端的所有请求。
Consistency level用于指定多少个Node返回写成功之后,coordinator给客户端返回成功。例如:当备份数量设置为3,Consistency level设置为1时,写请求会分发到三个Node上,
只要有一个Node返回写成,则coordinator给客户端返回成功。
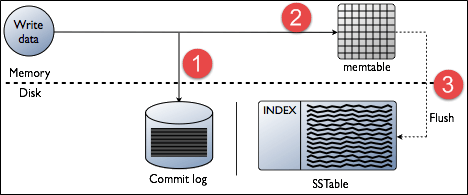
写请求在Node内部的实现步骤:首先会提交Commit Log记录,然后将数据写到Mem-table缓存中。Mem-table中的数据刷新到磁盘SSTable的时机:
- Mem-table分配的内存空间被写满
- Mem-table在内存中的存放时间超过了限制
- 用户手动刷新
SSTables存储格式
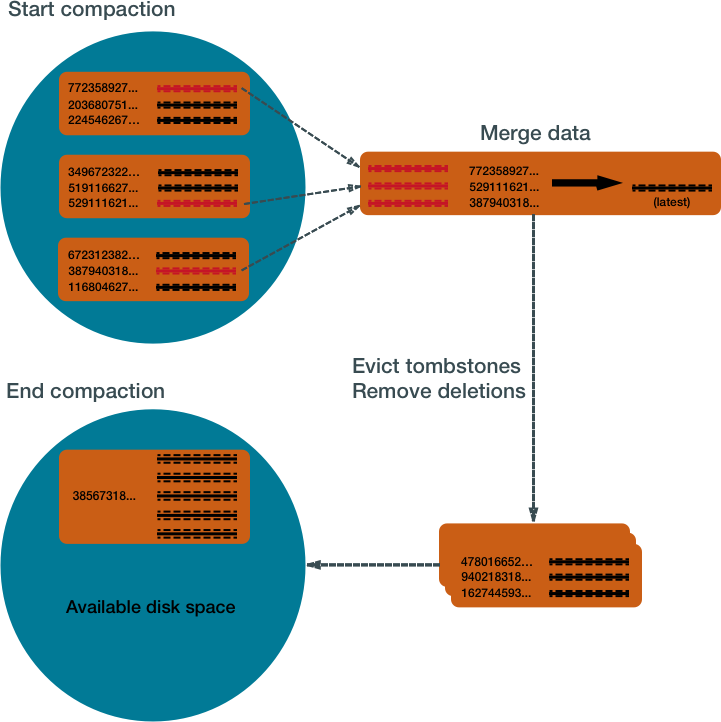
Mem-table中的数据每次刷新都会创建一个新的SSTables,并且对同一份数据的修改也是通过增加一份数据,而不是修改原有数据来实现的。 所以一份数据可能存在多个SSTables中,并且需要其他工具来辅助读操作(这也是为什么cassandra适用于写多读少的场景)。 Cassandra会定期合并SSTables并删除旧的数据,这种操作叫做压缩:首先收集同一个row key所有版本的数据,然后对比column数据中的版本号(时间戳),使用最新的版本号合并为一个最新的数据集, 这样可以增加读性能,避免在读操作时扫描所有SSTable表。
对于每个SSTable有下面这些结构与之对应:
- Data(Data.db)
实际存放数据的表 - Primary Index(Index.db)
raw key的索引,保存着对应数据在Data.db文件中的位置 - Bloom filter (Filter.db)
此表存放在内存中,用于检查数据是否在对应的SSTable中,这样可以减少对SSTable的磁盘访问。 - Compression Information (CompressionInfo.db)
包含未压缩数据的长度,块偏移和其他有关压缩信息的数据。 - Statistics (Statistics.db)
有关于SSTable内容的统计数据 - Digest (Digest.crc32, Digest.adler32, Digest.sha1)
A file holding adler32 checksum of the data file - CRC (CRC.db)
A file holding the CRC32 for chunks in an a uncompressed file. - SSTable Index Summary (SUMMARY.db)
A sample of the partition index stored in memory - SSTable Table of Contents (TOC.txt)
A file that stores the list of all components for the SSTable TOC - Secondary Index (SI_.*.db)
Built-in secondary index. Multiple SIs may exist per SSTable
Cassandra读操作
读操作和写操作类似,也是其中一个Node当作coordinator,根据备份数量和Consistency level来确定多少个备份返回成功,就视为请求成功。
如果不同备份返回的数据版本号不一致,coordinator会返回最新的版本给客户端,然后发送一个读修复命令给保存有旧数据的Node,触发他们同步更新数据。
读请求在Node内部的实现步骤,查找所有SSTable,将该row key的数据全部找出来,然后做合并操作:
- 在memtable中查找
- 如果开启了row cache功能,在row cache中查找
- 在Bloom filter中查找
- 如果开启了partition key cache功能,在partition key cache中查找partition index
- 如果在partition key cache找到则直接访问compression offset map,如果没有找到则到partition summary中查找partition index
- 通过partition index在compression offset map中查找数据的存放地址,加载磁盘数据
- 获取SSTable中的指定数据
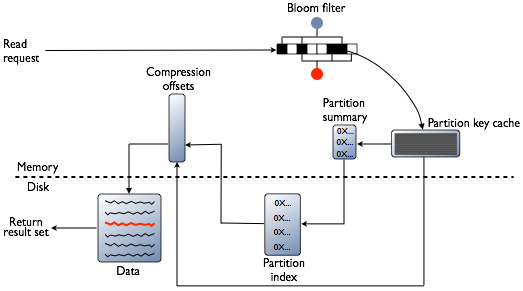
- Row cache
数据缓冲区,他会将SSTables中的一部分数据存储到内存中,以满足快速读取操作 - Partition Key Cache
Partition key的缓冲区,他会缓存Partition key对应的partition index - Partition Summary 分段存放key的索引,例如分段为20,则他会存放第1个key的位置以及第20个key的位置。找到分段之后去遍历分段找到对应的partition index
- Compression offset map
存放数据在磁盘中的存放地址,通过partition index找到对应数据的地址。
Node之间的通信协议Gossip
Gossip是用来在Cassandra集群中的各个结点之间传输结点状态的协议。它每秒都将运行一次,并将当前Cassandra结点的状态以及其所知的其它结点的状态与至多三个其它结点交换。通过这种方法,Cassandra的有效结点能很快地了解当前集群中其它结点的状态。同时这些状态信息还包含一个时间戳,以允许Gossip判断到底哪个状态是更新的状态。
除了在集群中的各个结点之间交换各结点的状态之外,Gossip还需要能够应对对集群进行操作的一系列动作。这些操作包括结点的添加,移除,重新加入等。为了能够更好地处理这些情况,Gossip提出了一个叫做Seed Node的概念。其用来为各个新加入的结点提供一个启动Gossip交换的入口。在加入到Cassandra集群之后,新结点就可以首先尝试着跟其所记录的一系列Seed Node交换状态。这一方面可以得到Cassandra集群中其它结点的信息,进而允许其与这些结点进行通讯,又可以将自己加入的信息通过这些Seed Node传递出去。由于一个结点所得到的结点状态信息常常被记录在磁盘等持久化组成中,因此在重新启动之后,其仍然可以通过这些持久化后的结点信息进行通讯,以重新加入Gossip交换。而在一个结点失效的情况下,其它结点将会定时地向该结点发送探测消息,以尝试与其恢复连接。但是这会为我们永久地移除一个结点带来麻烦:其它Cassandra结点总觉得该结点将在某一时刻重新加入集群,因此一直向该结点发送探测信息。此时我们就需要使用Cassandra所提供的结点工具了。
参考:
Cassandra Architecture
Apache Cassandra Architecture
Data replication
How is data read?
How is data maintained?
How is data written?
Cassandra - Data Model
Cassandra简介
Examples of read consistency levels
Multiple datacenter write requests